03. 微调
03 微调 V1 RENDER V2
迁移学习
迁移学习是指调整预训练的神经网络并应用到新的不同数据集上。
根据以下两个方面:
- 新数据集的大小,以及
- 新数据集和原始数据集之间的相似性
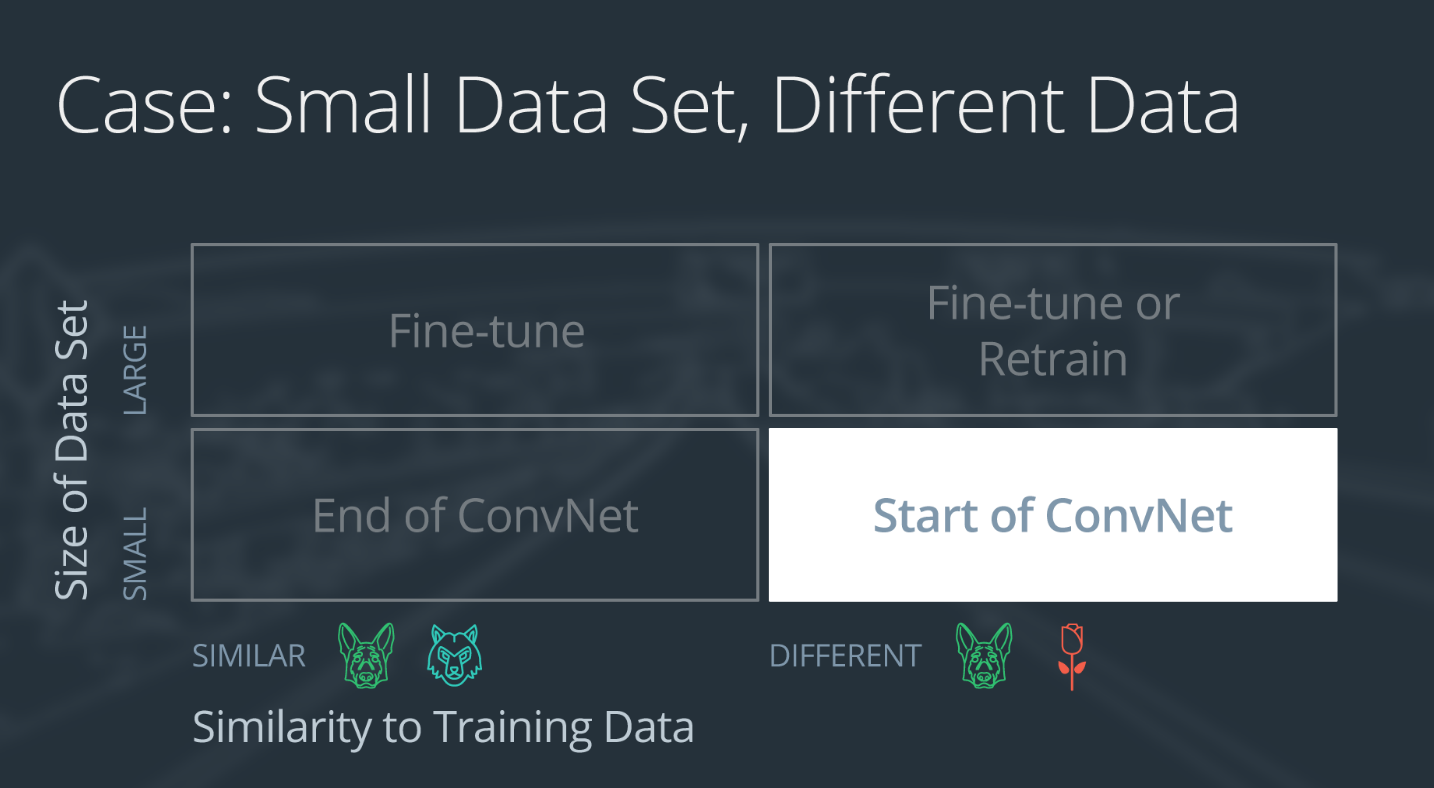
使用迁移学习的方式将不同。包括以下四大情形:
- 新数据集很小,新数据和原始训练数据相似
- 新数据集很小,新数据和原始训练数据不同
- 新数据集很大,新数据和原始训练数据相似
- 新数据集很大,新数据和原始训练数据不同

使用迁移学习的四种情形
大型数据集可能有 100 万张图像。小型数据集可能有 2000 张图像。大型数据集和小型数据集的划分依据具有主观性。对小型数据集使用迁移学习时需要注意过拟合问题。
小狗图像和狼图像属于相似的图像;它们具有共同的特征。花朵图像数据集和小狗图像数据集则很不同。
四种迁移学习情形分别具有自己的应用方式。在下面的几个部分,我们将分别讨论每种情形。
演示网络
为了解释每个情形的工作原理,我们首先介绍一个预训练的卷积神经网络,并解释如何针对每种情形调整网络。示例网络包含三个卷积层和三个全连接层。
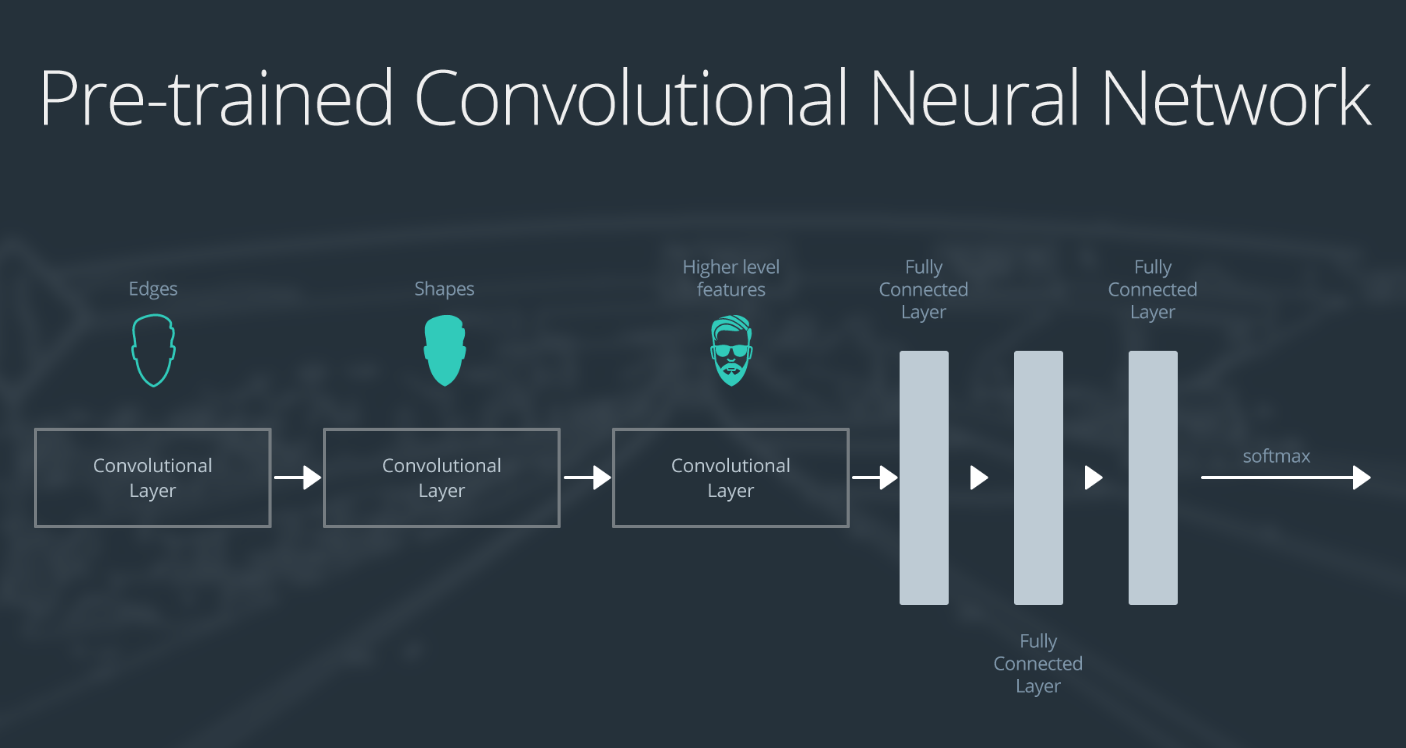
预训练 CNN 的层级预览
下面概述了该卷积神经网络的作用:
- 第一个层级将检测图像中的边缘
- 第二个层级将检测形状
- 第三个卷积层将检测更高级特征
每个迁移学习情形都将以不同的方式使用预训练的卷积神经网络。
情形 1:小数据集,相似数据

情形 1:小数据集,相似数据
如果新数据集很小,并且与原始训练数据相似:
- 删除神经网络的末尾层级
- 添加一个新的全连接层,输出数量与新数据集中的类别数量一样
- 随机化新全连接层的权重;冻结预训练网络的所有权重
- 训练网络以更新新全连接层的权重
为了避免过拟合小数据集,原始网络的权重将保持不变,而不是重新训练权重。
由于数据集相似,所以两个数据集的图像将具有相似的更高级特征。所以,大多数或所有预训练神经网络层级已经包含关于新数据集的相关信息,应该保留这些信息。
可视化结果为:
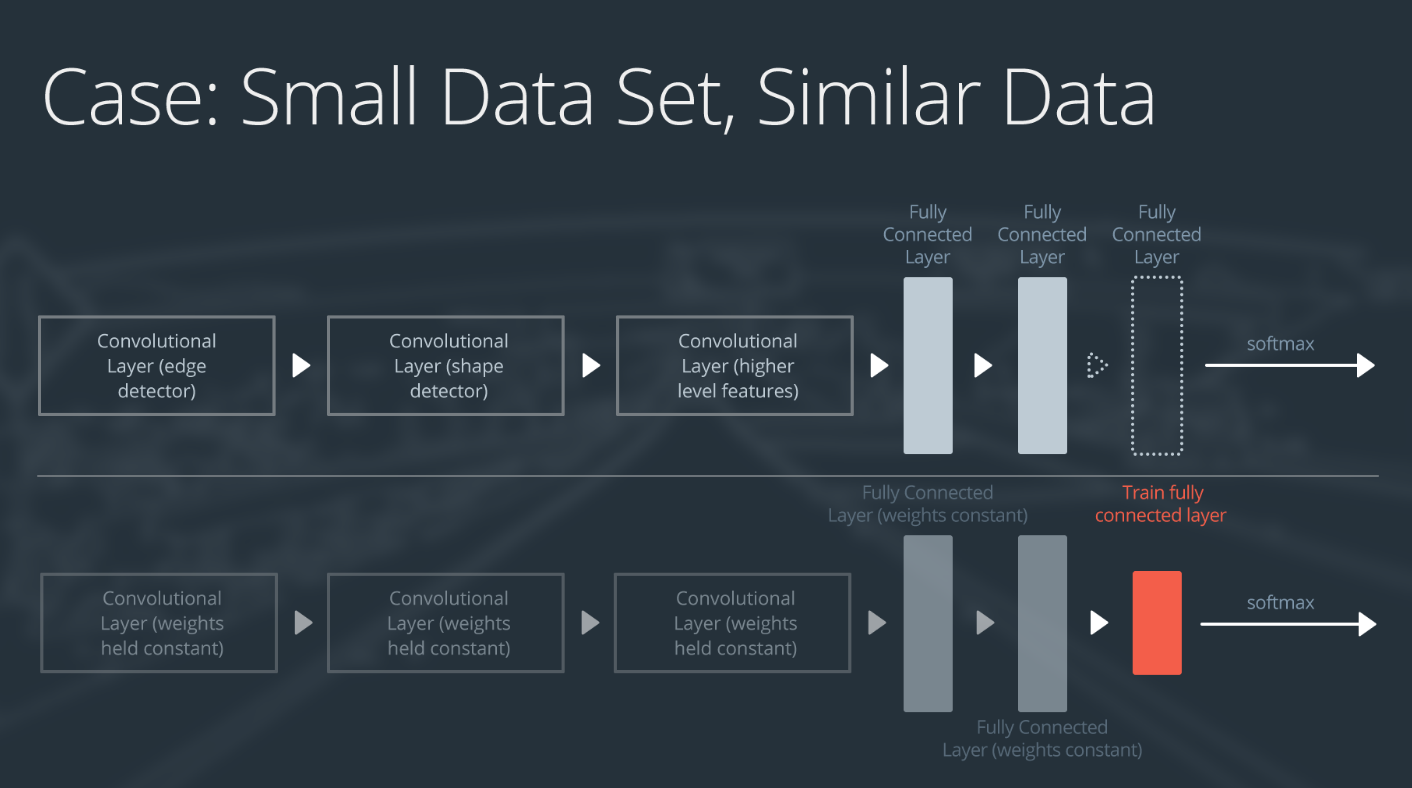
在 CNN 的末尾添加并训练全连接层
情形 2:小数据集,不同的数据
情形 2:小数据集,不同的数据
如果新数据集很小,并且与原始训练数据不同:
- 删除靠近网络开头的大多数预训练层级
- 在剩余预训练层级后面添加一个新的全连接层,输出数量与新数据集中的类别数量一样
- 随机化这个新的全连接层的权重;冻结预训练网络的所有权重
- 训练网络以更新这个新的全连接层的权重
由于数据集很小,所以依然需要避免过拟合问题。为了避免过拟合,原始神经网络的权重将保持不变,与第一种情形一样。
但是原始训练集和新数据集的更高级特征不一样。在这种情形下,新网络将仅使用包含更低级特征的层级。
可视化结果为:
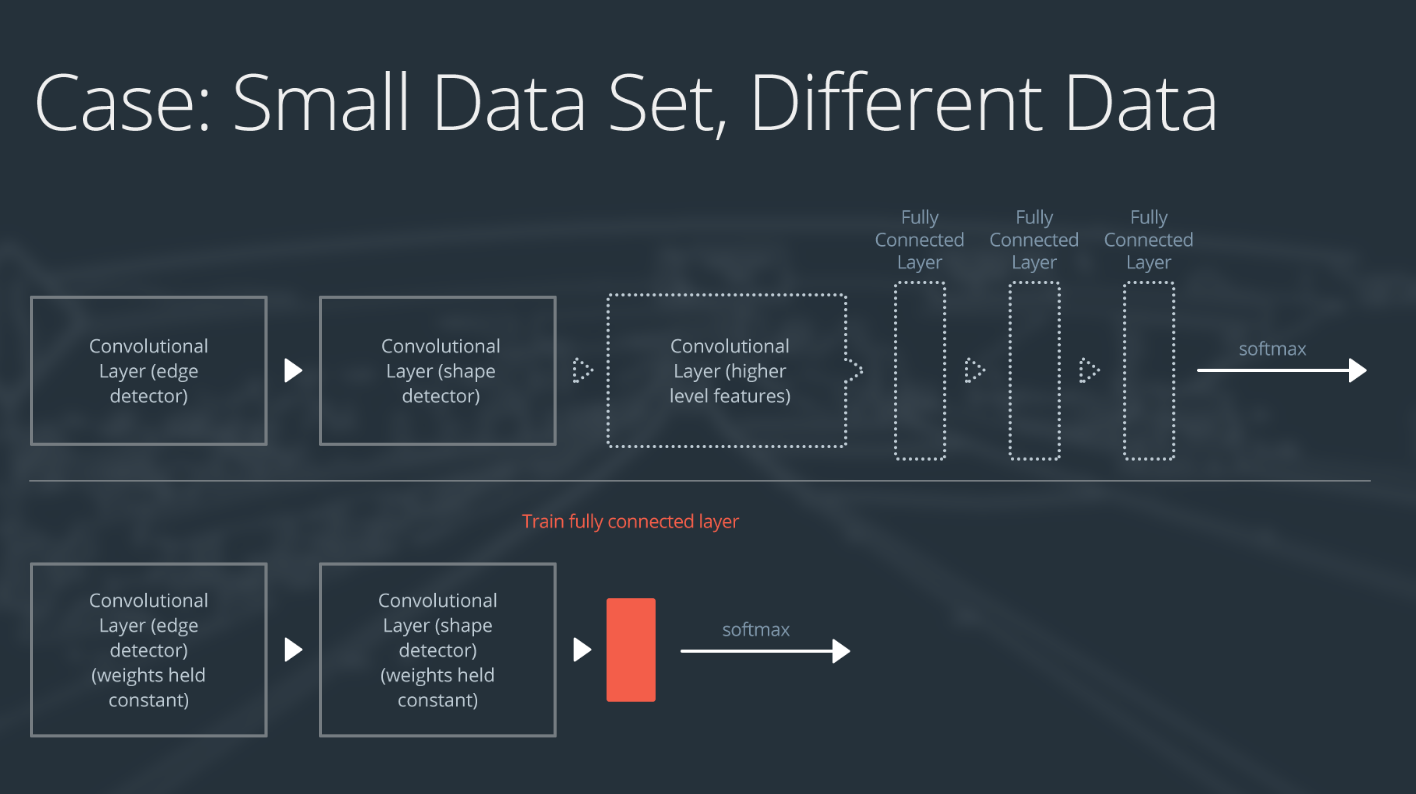
删除模型开头以外的所有层级,并在末尾添加和训练一个线性层级。
情形 3:大型数据集,相似数据

情形 3:大型数据集,与 ImageNet 或预训练数据集相似
如果新数据集很大,并且与原始训练数据相似:
- 删除最后的全连接层,并替换为输出数量与新数据集中的类别数量一样的层级
- 随机初始化新全连接层的权重
- 使用预训练的权重初始化剩余的权重
- 重新训练整个神经网络
用大型数据集训练时,过拟合并不是严重的问题,所以可以重新训练所有权重。
因为原始训练集和新数据集的更高级特征一样,所以使用整个神经网络。
可视化结果为:
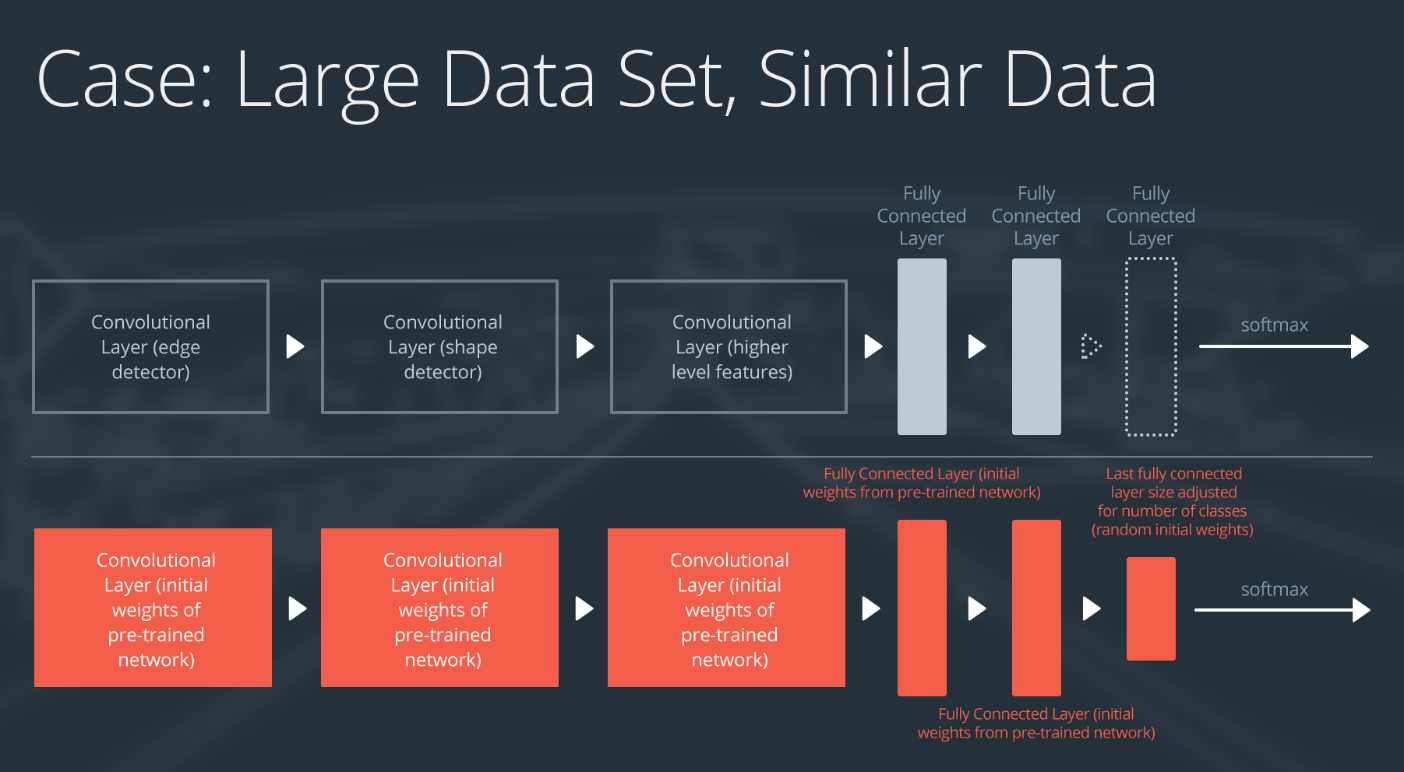
使用预训练权重作为起点!
情形 4:大型数据集,不同的数据

情形 4:大型数据集,与原始数据集不同
如果新数据集很大,并且与原始训练数据不同:
- 删除最后的全连接层,并替换为输出数量与新数据集中的类别数量一样的层级
- 从头训练网络,并随机初始化权重
- 或者采用和“大型数据集,相似数据”情形一样的策略
虽然数据集和训练数据不同,但是将初始权重设为预训练网络中的权重可能会加快训练速度。所以这种情形和“大型数据集,相似数据”情形完全一致。
如果将预训练网络设为起始网络没有生成成功的模型,你可以选择去随机初始化卷积神经网络权重,并从头训练网络。
可视化结果为:
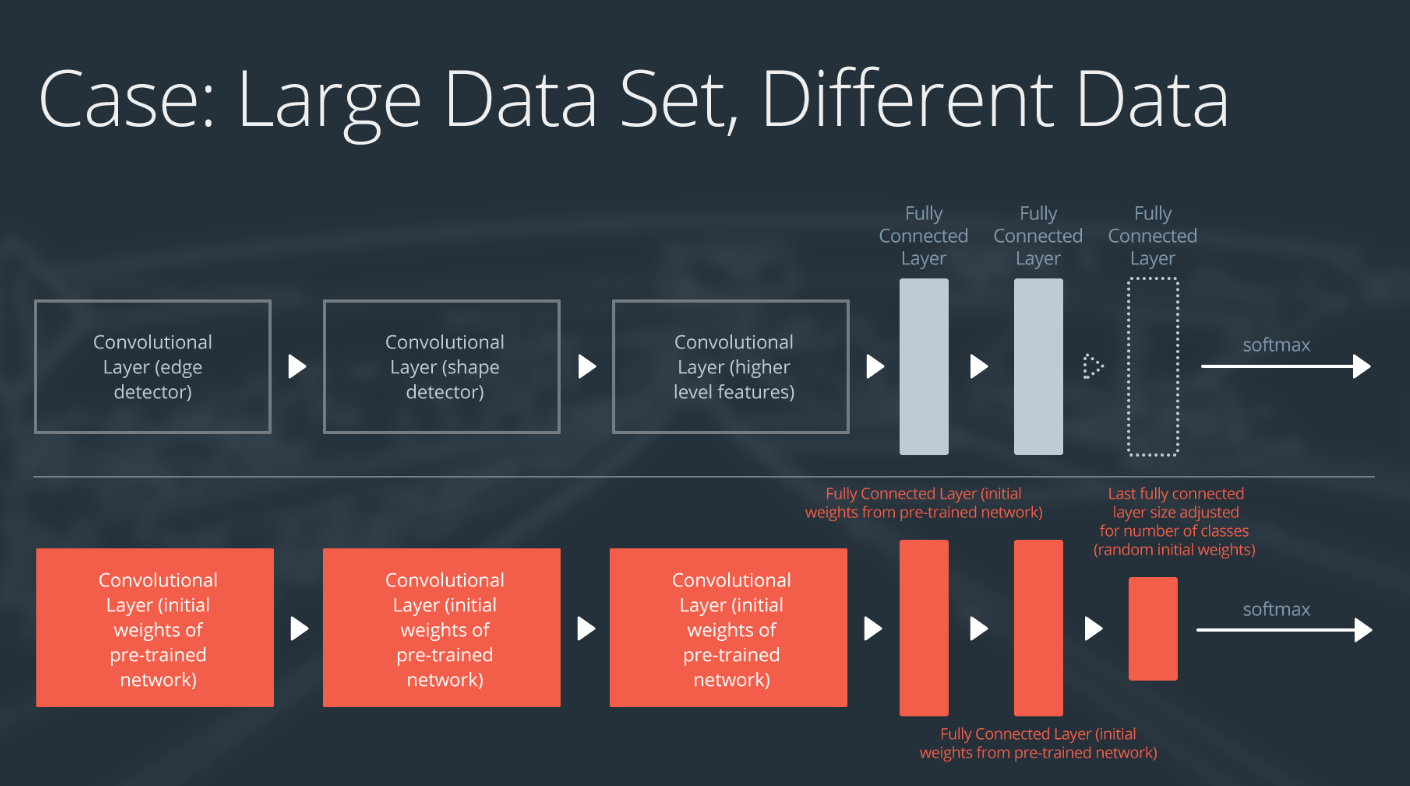
微调或重新训练整个网络